
automazione-it.com
17
'22
Written on Modified on
Mouser News
Archiviazione computazionale: spostare gli algoritmi, non i dati
Di pari passo con l'incremento dell'uso delle reti neurali per l'apprendimento automatico, è aumentata la necessità di elaborare enormi quantità di dati.

L'approccio tradizionale seguita dai dipartimenti IT è sempre stato quello di trasferire i dati laddove sia presente un algoritmo in grado di elaborarli. Tuttavia, dataset di grandissime dimensioni (fino a 1 PB) sono oramai molto comuni. Se si considera che l'algoritmo preposto all'elaborazione di questi dati potrebbe avere dimensioni dell'ordine della decina di Mbyte, il concetto di processare i dati in prossimità del dispositivo di archiviazione sta riscuotendo un'attenzione sempre maggiore. In questo articolo verranno analizzati e concetti e l'architettura alla base dell'archiviazione computazionale e verrà illustrato come un CSP (Computational Storage Processor) possa essere utilizzato per fornire l'accelerazione hardware e garantire un aumento di prestazioni per un'ampia gamma di processi (task) compute-intensive (ovvero che richiedono un gran numero di elaborazioni) senza provocare un sovraccarico (overhead) per il processore host.
Dataset sempre più grandi
Negli ultimi anni si è assistito a un sensibile incremento dell'uso degli algoritmi basati su reti neurali, in particolar modo nei settori automotive, industriale, della sicurezza e consumer. Alcuni algoritmi, come quelli utilizzati dai sensori IoT posizionati alla periferia della rete (edge) elaborano quantità molto ridotte di dati e quindi utilizzano algoritmi caratterizzati da codici che utilizzano poco spazio. L'uso di algoritmi di apprendimento automatico (machine learning) alla periferia della rete sta aumentando in maniera esponenziale in concomitanza con il progredire delle funzionalità di elaborazione degli “engine” delle reti neurali e dei microcontrolllori embedded a basso consumo.
Nelle applicazioni industriali e automotive si fa ampio ricorso all'elaborazione della visione per il rilevamento degli oggetti utilizzando una rete neurale specifica denominata rete neurale convoluzionale CNN (Convolutional Neural Network). In una semplice applicazione di elaborazione della visione sarà possibile, a esempio, rilevare se un'etichetta è apposta correttamente sulla bottiglia posta su una linea di imbottigliamento operante a elevata velocità. Compiti più complessi potrebbero richiedere lo smistamento di un determinato tipo di frutta, a esempio mele, in base a dimensioni, condizioni e varietà. Le applicazioni di elaborazione della visione in real time, tipiche del settore automotive, richiedono l'uso di reti neurali caratterizzate da prestazioni superiori in grado di identificare e classificare più oggetti. Le reti neurali sono ampiamente utilizzate anche nel campo della ricerca scientifica. Per esempio è necessario elaborare dataset di grandi dimensioni per analizzare i dati acquisiti da satelliti per il rilevamento a distanza e da reti di sensori sismici dislocati in tutto il globo.
Nella maggior parte delle applicazioni di apprendimento automatico è necessario aumentare la probabilità di eseguire osservazioni e classificazioni corrette. Per raggiungere questo obiettivo sono necessari dataset di grandi dimensioni per l'addestramento, il che implica lo spostamento, l'elaborazione e l'archiviazione di dataset che possono raggiungere dimensioni di 1 PB.
Archiviazione computazionale
I dispositivi di archiviazione basati su flash NAND hanno trovato ampia diffusione nell'ultimo decennio. Destinate inizialmente alle applicazioni di archiviazione di fascia alta, le memorie NAND per le unità a stato solido (SSD) hanno progressivamente sostituito le tradizionali unità a disco magnetico nella maggior parte dei computer laptop e desktop. Questo nuovo approccio alla memorizzazione, abbinato all'introduzione del protocollo NVMe (Non Volatile Memory express) e all'aumento della velocità di trasferimento dati reso possibile dalla connettività tramite interfacce PCIe, ha fornito l'opportunità di ripensare alle modalità di utilizzo delle risorse di elaborazione e di archiviazione. Le tecnologie di archiviazione basate su NVMe sono caratterizzate da maggiore ampiezza di banda, ridotta latenza e densità di archiviazione più elevata.
In un'architettura di elaborazione tradizionale (Fig.1), i dati vengono trasferiti tra i piani di elaborazione e di archiviazione. Le risorse di elaborazione vengono utilizzate per spostare i dati e processarli, nonché eseguire operazioni di compressione e decompressione, oltre a una miriade di altri compiti (task) correlati al sistema. In un approccio di tipo tradizionale, le risorse di elaborazione disponibili svolgono un considerevole carico di lavoro.
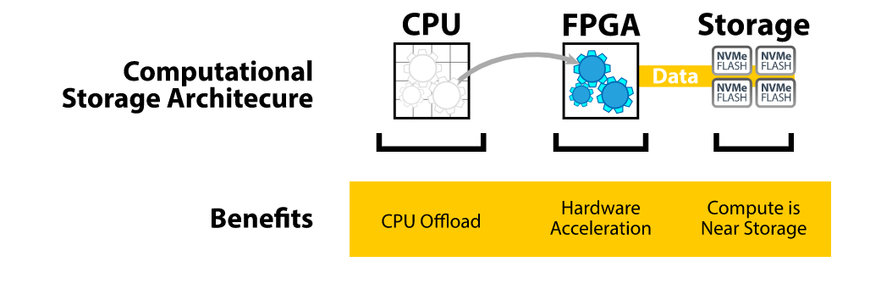
Figura 2 – Approccio basato su un'architettura di archiviazione computazionale (fonte: Bittware).
Un approccio più efficiente all'elaborazione prevede il ricorso a un'architettura di archiviazione computazionale (fig. 2), in cui i compiti di elaborazione vengono trasferiti a un acceleratore hardware che solitamente è basato su FPGA. L'acceleratore è collegato a un dispositivo di archiviazione flash posizionato nelle immediate vicinanze che utilizza il protocollo NVMe. Poichè i dati si trovano in prossimità del luogo dove si svolge l'elaborazione, la CPU non deve più effettuare operazioni di trasferimento dati, con tutti gli oneri che ciò comporta. L'FPGA svolge il ruolo di processore di archiviazione computazionale (CSP – Computational Storage Processor), in grado quindi di eseguire processi compute-intensive – come a esempio compressione, cifratura, inferenza basata su reti neurali – al posto della CPU.
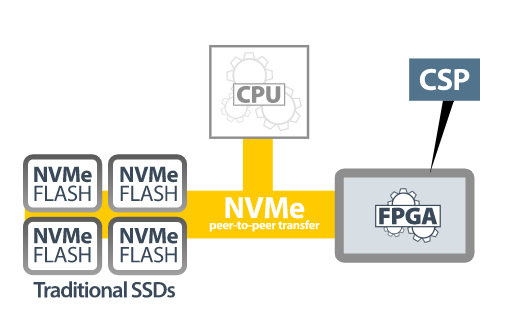
Figura 3 – Un processore di archiviazione computazionale (CSP) (fonte: Bittware).
IA-222-U2: il processore CSP basato su FPGA di BittWare
Un esempio di processore di archiviazione computazionale è il dispositivo IA-220-U2 di BittWare (link Mouser?). Questo processore include un FPGA Intel Agilex con un massimo di 1,4 M elementi logici, fino a 16 GB di memoria DDR4 e quattro interfacce PCIe Gen4. La memoria SDRAM DDR4 è caratterizzata da una velocità di trasferimento dati massima di 2400 MT/s. Disponibile nel fattore di forma U.2 da 2,5” compatibile con SFF-8639 con dissipatore per il raffreddamento per convezione, il processore IA-220-U.2 è stato progettato per essere integrato in un array di archiviazione NVMe U.2 (fig. 4).

Figura 4 – Il processore IA-220-U2 di BittWare è progettato per essere integrato in un array di archiviazione U.2 standard (fonte: Bittware)
Questo processore di BittWare supporta l'”hot swapping”, ovvero il rimpiazzo “a caldo”, e assorbe una potenza massima di 20 W dall'alimentatore dell'host U.2. La disponibilità a bordo di un controllore SMBus conforme a NVMe-MI, la presenza di una funzione di controllo della flash dell'FPGa tramite SMBus e l'accesso, sempre mediante SMBus, ai sensori per il monitoraggio della temperatura e della tensione rendono questo processore adatto all'uso in datacenter e sistemi IT aziendali.
Nello schema a blocchi funzionale di IA-220-U2 di Bittware riportato in figura 5 vengono evidenziate le caratteristiche principali.
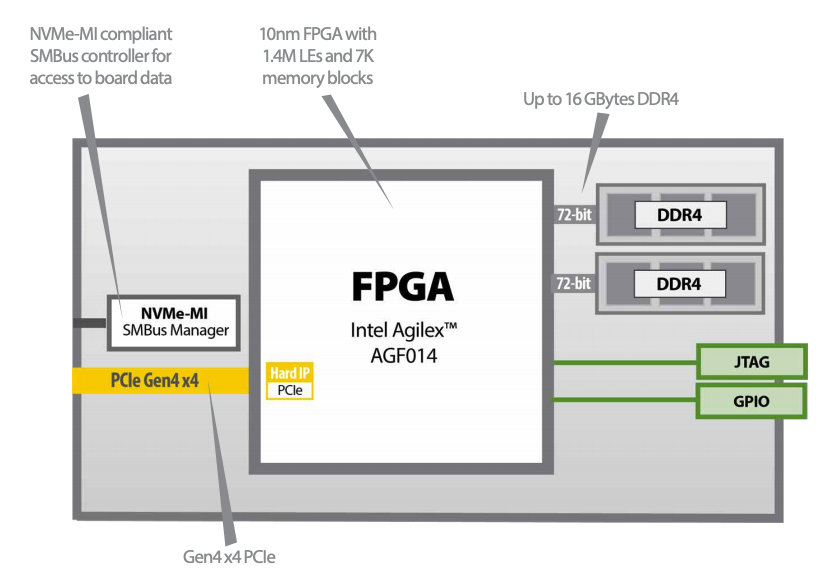
Figura 5 – Schema a blocchi funzionale del processore IA-220-U2 di BittWare (fonte: BittWare)
IA-220-U2 è stato progettato per lo svolgimento di numerosi compiti di accelerazione, tra cui inferenza algoritmica, compressione, crittografia e hashing (creazione di una stringa di lunghezza fissa a partire da qualunque file o testo), ricerca di immagini e ordinamento (sorting) di database e deduplicazione.
Implementazione di un CSP mediante IA-220-U2
Il processore IA -220-U2 di Bittware può essere programmato dall'utente per lo sviluppo di applicazioni custom oppure fornito come soluzione pre-configurata utilizzando l'IP NoLoad di Eideticom.
BittWare fornisce un SDK che include driver PCIe, utility per il monitoraggio della scheda e librerie per la scheda che rappresenta un valido ausilio nel caso di sviluppo personalizzato. Per la realizzazione di applicazioni FPGA è possibile utilizzare Quartus Prime Pro di Intel, oltre a flussi di progetto e toolchain di sintesi ad alto livello.
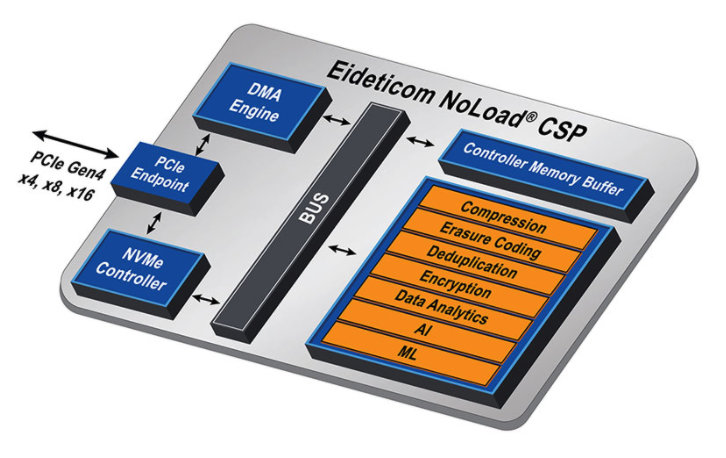
Figura 6 – Caratteristiche hardware dell’IP NoLoad di Eideticom (fonte: BittWare)
L’IP NoLoad di Eideticom include uno stack software completo e integrato di tipo plug-and-play basato sul modulo U.2 di BittWare come soluzione pre-configurata. Esso ospita un insieme di servizi CSS (Computational Storage Device) accelerato mediante hardware che sono evidenziati in arancio in figura 6.
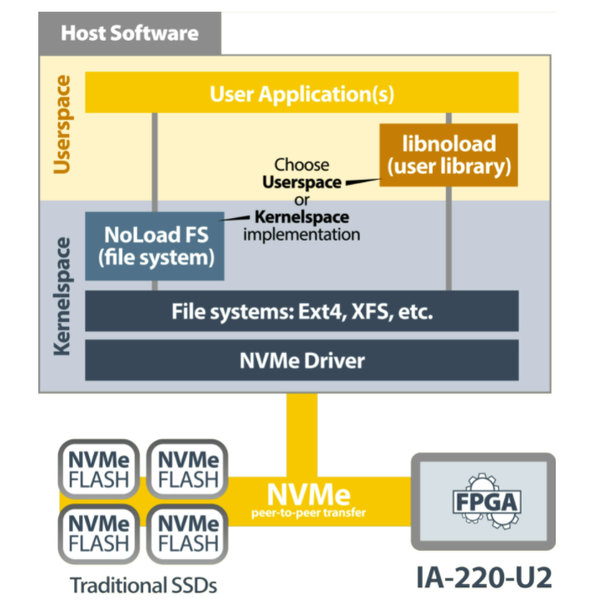
Figura 7 – Lo stack software dell’IP NoLoad di Eideticom (fonte: BittWare)
I componenti software dell’IP NoLoad (Fig. 7) includono un file system “impilato” (stacked) nello spazio kernel e un driver NVMe che utilizza i servizi CSS NoLoad, oltre a Libnoload, lo spazio utente orientato all’applicazione.
Grazie a una soluzione come NoLoad di Eideticom, agnostica nei confronti della CPU, che permette di trasferire l’onere dell’elaborazione all'esterno della CPU, è possibile migliorare di un fattore fino a 40 volte la qualità del servizio (QoS), riducendo nel contempo sia i costi complessivi di possesso sia i consumi.
Throughput accelerato con il trasferimento dei processi compute-intensive
L’implementazione di un’architettura di archiviazione computazionale basta su NVMe assicura un notevole incremento della prestazioni e una sensibile riduzione dei consumi in tutte le applicazioni che prevedono l'elaborazione di grandi volumi di dati. Questo approccio consente di ridurre la necessità di spostare i dati dall’unità di archiviazione alla CPU (e viceversa) trasferendo i processi compute-intensive a un processore di archiviazione computazionale basato su FPGA. L’archiviazione dei dati in prossimità del punto di elaborazione su un array di flash NAND che supporta NVMe permette di ridurre consumi, latenza e ampiezza di banda richiesta.
www.mouser.com
Richiedi maggiori informazioni…
